Configurar Spool en origen de datos
Introducción
Spool es una funcionalidad que permite entregar grandes volúmenes de datos en las APIs.
Por buenas prácticas las APIs entregan de forma sincrónica hasta un máximo de 10.000 registros, aunque en algunos casos de uso puede ser necesario entregar cantidades mayores.
Para esos casos es que se utiliza la funcionalidad de Spool que permite entregar en forma de archivos grandes volúmenes de datos.
En nombre de la funcionalidad en Vor-Tex se inspira en el significado de Spool de las bases de datos. En el contexto de bases de datos "spool" se refiere a la funcionalidad de volcar (grabar o registrar) la salida de una sesión en un archivo.
Cuando un origen de datos tenga habilitada la función de Spool, Vor-Tex ejecutará el origen de datos y guardará el resultado en un archivo que podrá ser descargado por el usuario.
Por definición, las ejecuciones de métodos de APIs asociados a orígenes de datos con Spool activado son asincrónicas.
Configuración del Origen de datos
La configuración de Spool se realiza en los orígenes de datos.
Una vez configurado el origen de datos, en el segundo paso puede activar la funcionalidad de Spool y aplicar configuraciones adicionales.
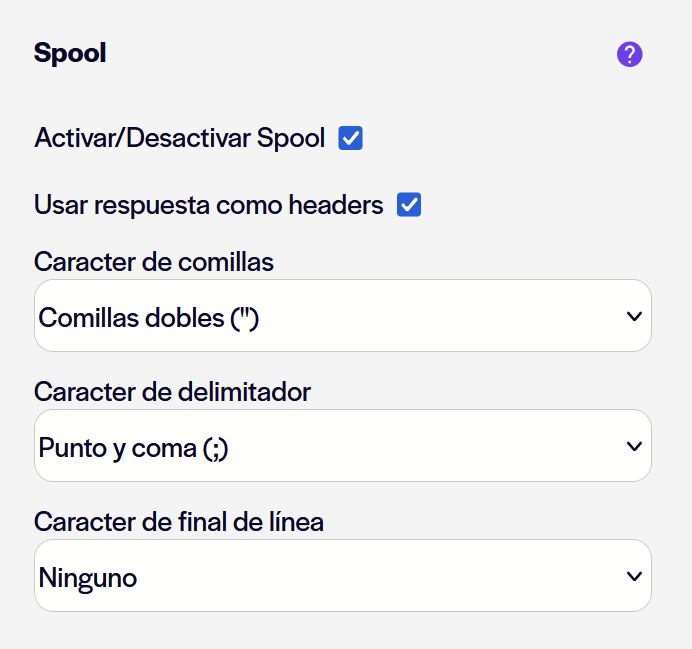
Usar atributos como cabeceras: si está activado se utilizará la primera fila, los atributos o nombres de las columnas como cabeceras del archivo generado.
Valores con comillas: permite configurar comillas dobles para encerrar el texto o los valores.
Caracter de delimitador: permite definir el caracter que separará los valores. Si no selecciona ninguno, por defecto se utilizará la coma.
Caracter de final de línea: permite definir la cadena de caracteres usada para terminar las líneas producidas. Por defecto es '\r\n' .
Una vez aplicadas las configuraciones, guarde el origen de datos y continúe con la creación de la vista de datos.
Crear vista de datos
Al crear la vista de datos no habrá selección y previsualización de los datos. De todas formas, puede configurar los parámetros, metadatos y multientorno.
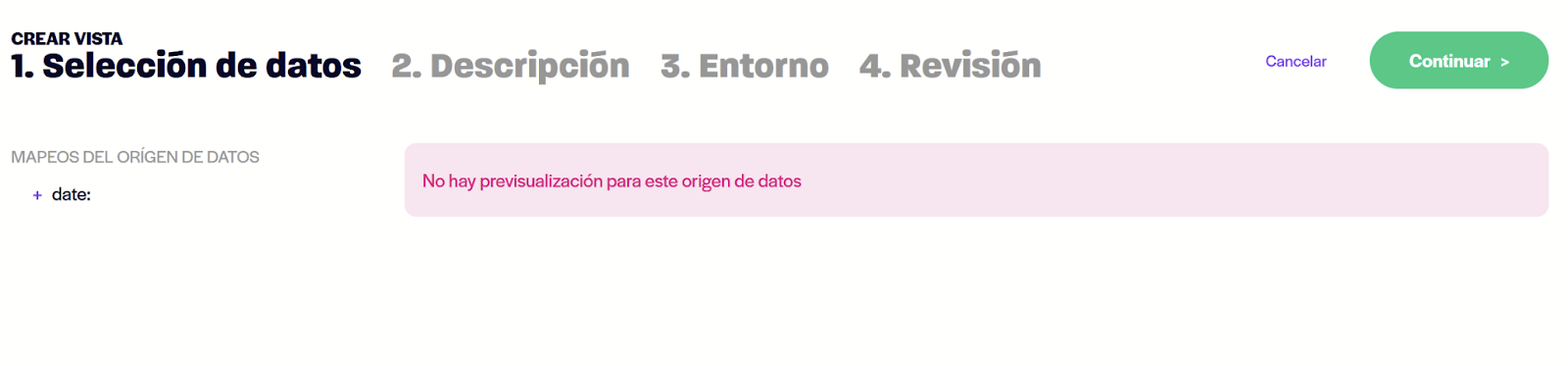
Para agregar un método seleccione en su API la vista creada. Una vez seleccionada la vista podrá configurar el método como en el resto de los casos, con la diferencia de que en este caso no deberá configurar plantillas de salida.

Una vez que haya guardado su método, publique la API.
Ejecutar método Spool
Primera solicitud: Ejecución de la tarea
En caso que la ejecución sea exitosa, la primera solicitud entregará un identificador de tarea en el atributo “uuid”.

{
"message": "Response is not ready call later with uuid >> 6a2f32af-a54c-4640-9a23-ea974a9c90c0",
"code": 409,
"uuid": "6a2f32af-a54c-4640-9a23-ea974a9c90c0"
}
Segunda solicitud: Obtener resultado
Para obtener el resultado, deberá ejecutar una segunda solicitud al mismo método, aunque agregando la cabecera X-UUID con el valor obtenido en la solicitud anterior.
curl 'example.com/accounts/v1/accounts' \
--header 'Authorization: ************' \
--header 'X-UUID: 302d9bbf-f789-4d46-9dba-c0210f3d7c98'
Casos de uso
Generación de Reportes Financieros:
Ejemplo: Un sistema de análisis financiero que proporciona reportes trimestrales o anuales detallados.
Uso: La API recibe una solicitud para generar un reporte financiero detallado y luego procesa los datos en segundo plano. Una vez completado el reporte, la API proporciona un enlace de descarga al archivo generado.
Beneficios
Mejora de la Experiencia del Usuario: Los usuarios no tienen que esperar mientras se procesan grandes volúmenes de datos.
Eficiencia en el Uso de Recursos: Permite el procesamiento en segundo plano, optimizando el uso de recursos del sistema.
Escalabilidad: Facilita el manejo de grandes volúmenes de datos, permitiendo que el sistema escale de manera eficiente.
Confiabilidad: Reduce el riesgo de tiempos de espera prolongados o bloqueos del sistema, mejorando la fiabilidad del servicio.
Estos casos de uso destacan cómo las APIs asincrónicas pueden ser extremadamente útiles para manejar grandes volúmenes de datos, proporcionando una manera eficiente y escalable de generar y entregar archivos de gran volumen.
Related Articles
Orígenes de datos desde Bases de datos
Resumen El conector a Bases de datos ofrece todas las capacidades necesarias para conectarse a este tipo de orígenes. Esta opción permite recolectar datos desde diferentes tipos de bases de datos o configurar acciones de escritura, para luego crear ...Orígenes de datos desde servicios web REST/json
Resumen El conector a servicios web REST/JSON ofrece todas las capacidades necesarias para conectarse a este tipo de orígenes. Esta opción permite recolectar datos desde servicios web REST/JSON o configurar acciones de escritura, para luego crear ...Qué es una vista de datos
Resumen La plataforma no requiere de un proceso ETL off-line para extraer los datos desde los orígenes, sino que asociadas a la vista se encuentran un conjunto de reglas que el motor de datos interpreta para consultar la fuente a demanda o ...Spool: particionado de datos
Introducción En el contexto de la gestión de APIs, el término Spool hace referencia a una técnica que permite almacenar temporalmente datos en un espacio intermedio, facilitando la distribución o procesamiento. Este mecanismo resulta particularmente ...Orígenes de datos desde URLs
Resumen El conector de URLs permite recolectar datos desde protocolos HTTP(s) y FTP. Para recolectar datos desde un archivo alojado en una URL, debes ir a Orígenes de Datos → Desde URLs Configuración Ingresar una URL con un enlace válido desde donde ...